 顯微成像
顯微成像 結(jié)構(gòu)分析
結(jié)構(gòu)分析 成分分析
成分分析 現(xiàn)場(chǎng)/云現(xiàn)場(chǎng)
現(xiàn)場(chǎng)/云現(xiàn)場(chǎng) 物性分析
物性分析 熱學(xué)性能
熱學(xué)性能 聲光電磁
聲光電磁 同步輻射
同步輻射 原位測(cè)試
原位測(cè)試 材料加工
材料加工 力學(xué)性能
力學(xué)性能 環(huán)境試驗(yàn)
環(huán)境試驗(yàn) 顯微成像
顯微成像 病理檢測(cè)
病理檢測(cè) 細(xì)胞實(shí)驗(yàn)
細(xì)胞實(shí)驗(yàn) 動(dòng)物實(shí)驗(yàn)
動(dòng)物實(shí)驗(yàn) 微生物實(shí)驗(yàn)
微生物實(shí)驗(yàn) 測(cè)序平臺(tái)
測(cè)序平臺(tái) 代謝組學(xué)平臺(tái)
代謝組學(xué)平臺(tái) 臨床前CRO
臨床前CRO 生物信息學(xué)平臺(tái)
生物信息學(xué)平臺(tái) 單細(xì)胞組學(xué)
單細(xì)胞組學(xué) 第一性原理
第一性原理 分子動(dòng)力學(xué)
分子動(dòng)力學(xué) 量子化學(xué)
量子化學(xué) CAE仿真
CAE仿真 更多服務(wù)
更多服務(wù) 超算服務(wù)
超算服務(wù) 金屬
金屬 電池
電池 可靠性測(cè)試
可靠性測(cè)試 玻璃
玻璃 高分子材料
高分子材料 無(wú)機(jī)材料
無(wú)機(jī)材料 環(huán)境
環(huán)境 產(chǎn)品
產(chǎn)品 建材
建材 未知成分分析
未知成分分析當(dāng)前位置:生物測(cè)試 ? 生物信息學(xué)平臺(tái) ?
蛋白表達(dá)模式聚類(lèi)分析
99%
滿意度
蛋白表達(dá)模式聚類(lèi)分析
已 預(yù) 約:
124次
服務(wù)周期:
平均10個(gè)工作日完成
立即下單
咨詢價(jià)格
收藏
如有各類(lèi)設(shè)備采購(gòu)需求,請(qǐng)聯(lián)系專屬顧問(wèn)。
項(xiàng)目介紹
聚類(lèi)是基因表達(dá)數(shù)據(jù)分析中的重要工具 - 無(wú)論是在轉(zhuǎn)錄本還是蛋白質(zhì)水平上,這種無(wú)監(jiān)督分類(lèi)技術(shù)通常用于揭示隱藏在大型基因表達(dá)數(shù)據(jù)集中的結(jié)構(gòu)。其中大多數(shù)聚類(lèi)算法都會(huì)對(duì)數(shù)據(jù)進(jìn)行硬分區(qū),即每個(gè)基因或蛋白質(zhì)都精確分配給一個(gè)聚類(lèi)。如果群集分離良好,則硬群集是有利的,但是基因或蛋白質(zhì)表達(dá)數(shù)據(jù)通常不是這種情況,因?yàn)榛蚧虻鞍踪|(zhì)簇經(jīng)常重疊。另外,硬聚類(lèi)算法通常對(duì)噪聲非常敏感。為了克服硬聚類(lèi)的局限性,我們實(shí)施了軟聚類(lèi),軟聚類(lèi)具有更強(qiáng)的噪聲魯棒性,并且可以避免對(duì)基因或蛋白質(zhì)進(jìn)行先驗(yàn)的預(yù)過(guò)濾,這樣可以防止從數(shù)據(jù)分析中排除生物學(xué)相關(guān)的基因或蛋白質(zhì)。
分析方法
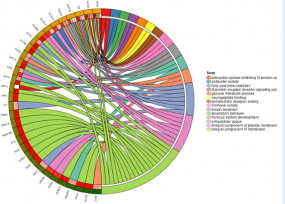
采用 Mfuzz 方法對(duì)不同連續(xù)樣本下蛋白的表達(dá)進(jìn)行聚類(lèi)分析。該方法采用了一種新的聚類(lèi)算法 fuzzy c-meansalgorithm,相比 K-means 等 hard clustering 算法,一定程度上降低了噪聲對(duì)聚類(lèi)結(jié)果的干擾,而且這種算法有效的定義了基因和 cluster 之間的關(guān)系。為了進(jìn)一步了解每個(gè) cluster 中蛋白參與的生物學(xué)過(guò)程,我們分別對(duì)對(duì)每個(gè) cluster 中的蛋白進(jìn)行了 GO 功能、KEGG 通路和蛋白結(jié)構(gòu)域的富集分析。
樣品要求
詳情請(qǐng)聯(lián)系技術(shù)經(jīng)理。
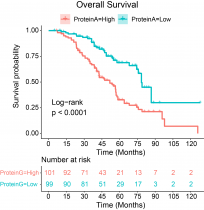
項(xiàng)目案例
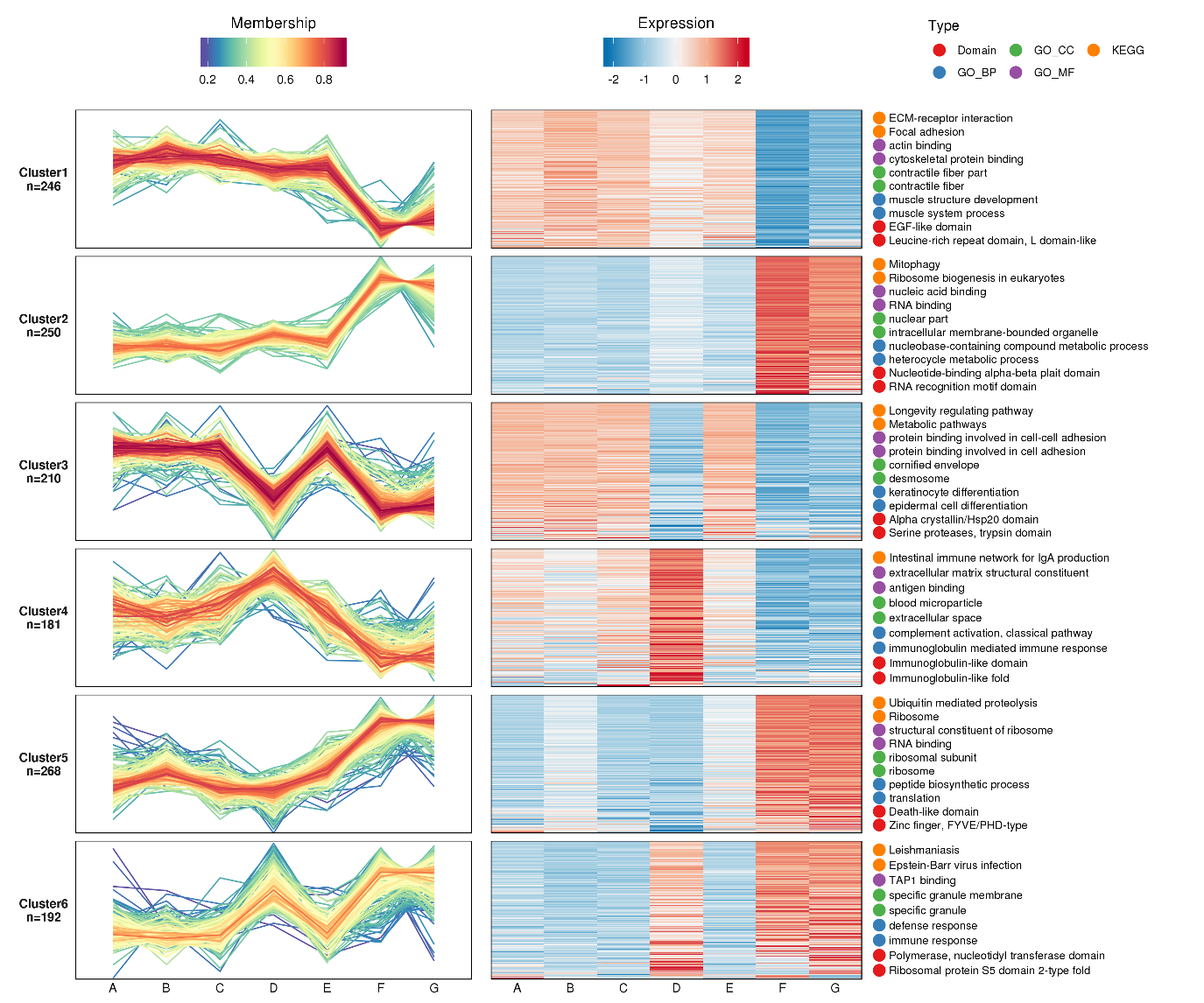
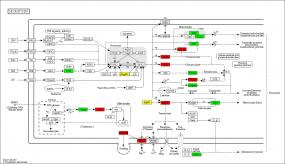
連續(xù)樣本表達(dá)模式聚類(lèi)分析結(jié)果圖

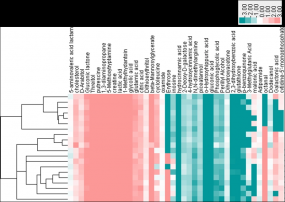
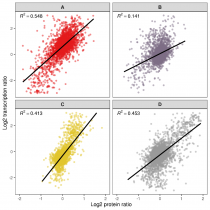
基于蛋白 cluster 的功能富集聚類(lèi)分析熱圖
學(xué)術(shù)文章
蛋白表達(dá)模式聚類(lèi)分析
立即下單


 蜀公網(wǎng)安備51010602000648號(hào)
蜀公網(wǎng)安備51010602000648號(hào)

